Research
I build AI foundation models for biomedicine that span scales, from organ-level radiology, through tissue-level pathology, down to the cell-and-molecular context of spatial biology, and translate them into tools that close the loop between clinical diagnosis and biomedical discovery.
My current work targets two long-term directions:
- Whole-patient foundation models that integrate imaging, pathology, clinical notes, and longitudinal signals to support diagnosis and treatment-response prediction.
- Spatial-omics foundation models that unify transcriptomics, proteomics, and morphology to enable biomarker discovery and disease-mechanism analysis.
Both directions are connected by generative modeling, vision-language models, and agentic reasoning as common interfaces across modalities.
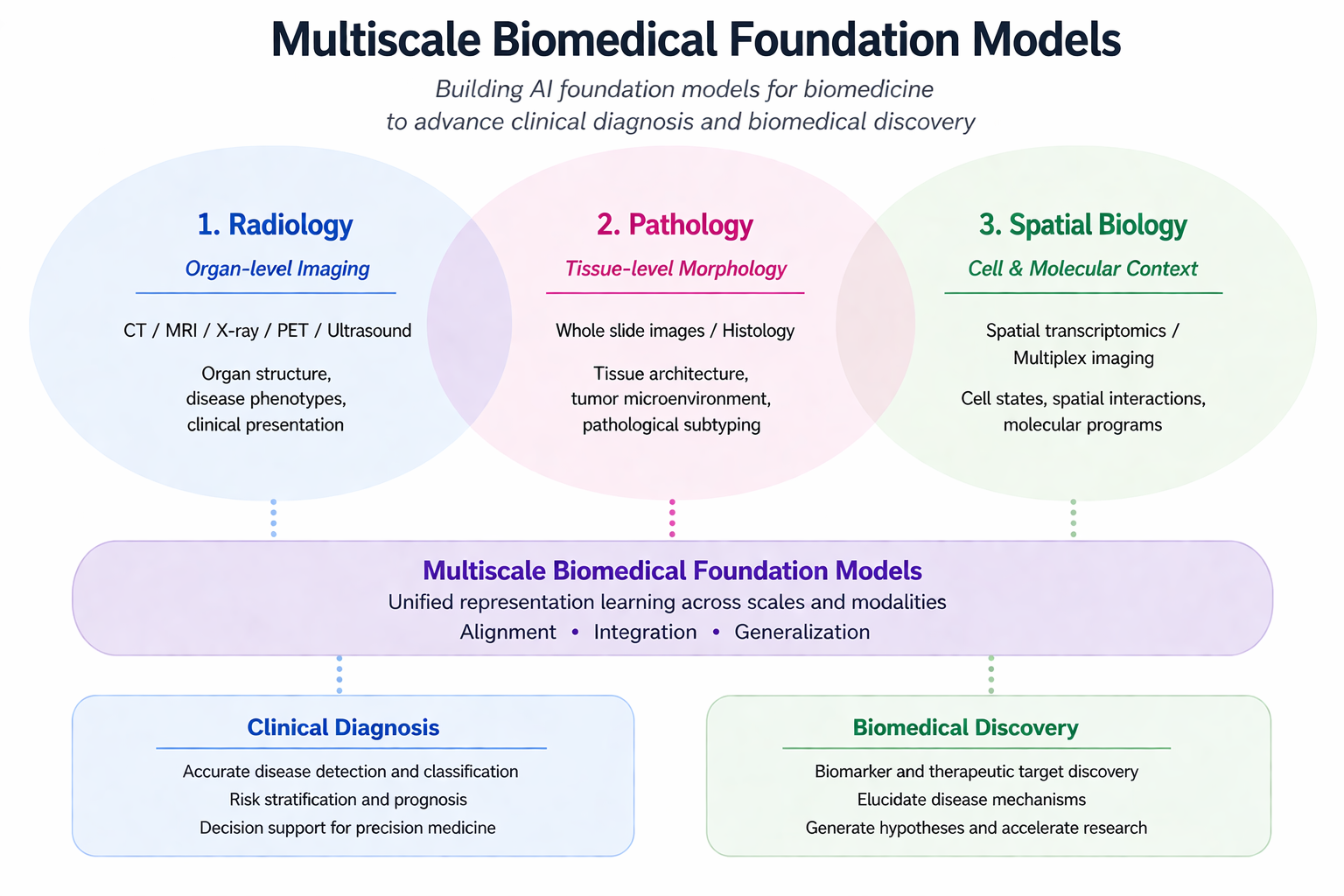
Concrete projects across scales
- Radiology & Pathology
- Spatial Biology
- SP-Mind (ICML 2026): an autonomous reasoning agent for spatial proteomics.
- Generative & VL
- MedITok: a unified tokenizer for medical image synthesis & interpretation.
- GMAI-VL-R1: reinforcement learning for medical reasoning.
Datasets & Benchmarks
- Radiology & Pathology
- AMOS (NeurIPS 2022 Oral): large-scale abdominal multi-organ segmentation; the most widely used multi-organ benchmark in the field.
- AMOS-MM (MICCAI 2024 Challenge): the first multimodal CT analysis benchmark for report generation and visual question answering.
- SlideInstruction: a WSI instruction dataset with 4.2K captions and 176K VQA pairs.
- SlideBench: a WSI multimodal benchmark spanning captioning and VQA across 21 clinical tasks.
- General
- DrugOOD (AAAI 2022 Oral): out-of-distribution generalization benchmark for AI-aided drug discovery.
- AutoBench (ICLR 2024): automatic benchmark using LLMs as aligners for evaluating vision-language models.
- GMAI-Reasoning10K: a 10K medical VQA instruction dataset for medical reasoning.